RAG vs Fine-Tuning: The CTO's Guide to Choosing the Right AI Architecture
This decision will either save your budget or drain it quietly!
There’s a pattern showing up across enterprise AI teams. They start with a strong model. Good APIs. Clean interfaces. Then things drift, especially in early-stage enterprise generative AI deployments.
Accuracy drops. Outputs become unreliable. Teams start adding patches. These include prompt tweaks, guardrails and retries. Eventually someone says, “We should fine-tune this.”
That’s usually the moment the system gets more expensive without actually getting better. The issue was not the model. It was the architecture, and more specifically poor AI system design.
This is the real fork. retrieval augmented generation vs fine-tuning. And for most enterprise systems, the wrong call here does not fail fast. It fails slowly, while costs stack up.
What you are Solving > What you are Building
Most discussions around AI architecture start at the wrong layer, especially when AI system design is not clearly defined in enterprise generative AI systems.
Teams ask:
Which model should we use?
Should we fine-tune?
What’s the best accuracy benchmark?
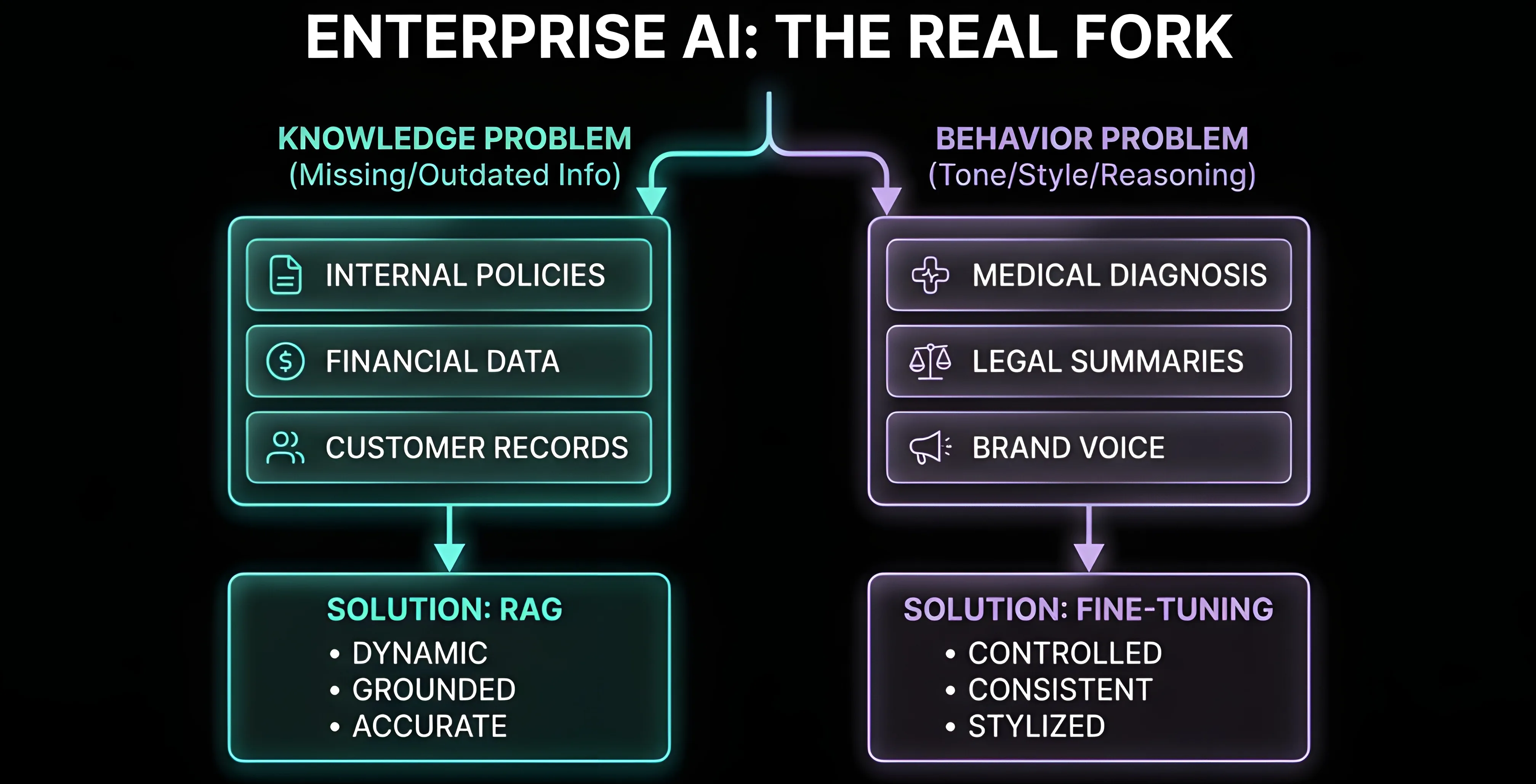
The better question is simpler than you think. It is, ‘are you trying to fix knowledge or behavior?’
Because these are completely different problems.
If your AI is missing information or outdated or inconsistent → it is a knowledge problem
If your AI responds incorrectly despite having the right context → it is a behavior problem
Almost every enterprise use case is the first one. Yet most teams reach for fine-tuning instead of adopting RAG enterprise AI approaches.
Why enterprise AI fails
LLMs do not throw errors when they are wrong. They generate answers that look right. That’s dangerous in environments where decisions depend on accuracy, especially in complex enterprise AI architecture setups.
You’ll see things like:
- Internal policies being “interpreted” incorrectly
- Financial summaries including fabricated numbers
- Customer interactions based on outdated data
This is why the focus has shifted from “better outputs” to reduce AI hallucinations in a way that holds under real usage.
The key point is that hallucinations are rarely solved by training more. They are solved by grounding better, which is where grounding LLMs becomes critical.
Stop trying to teach the model everything
This is where retrieval-augmented generation changes the equation.
Rather than relying on the model to hold all the knowledge internally, you keep knowledge separate from reasoning. This approach strengthens modern enterprise AI architecture by separating data and intelligence layers while supporting better AI cost optimization.
The system works like:
- Enterprise data is broken into chunks
- Converted into embeddings
- Stored in a vector database
- Retrieved dynamically during queries
The model no longer guesses. It responds using the data you provide at runtime. That shift from memory to retrieval is what makes RAG viable at scale and helps reduce AI hallucinations effectively.
Why RAG is becoming the default and not the alternative
Cost does not compound unpredictably
Fine-tuning introduces a cost curve that’s hard to control.
You pay for:
- Data preparation
- Training cycles
- Validation iterations
- Retraining as data evolves
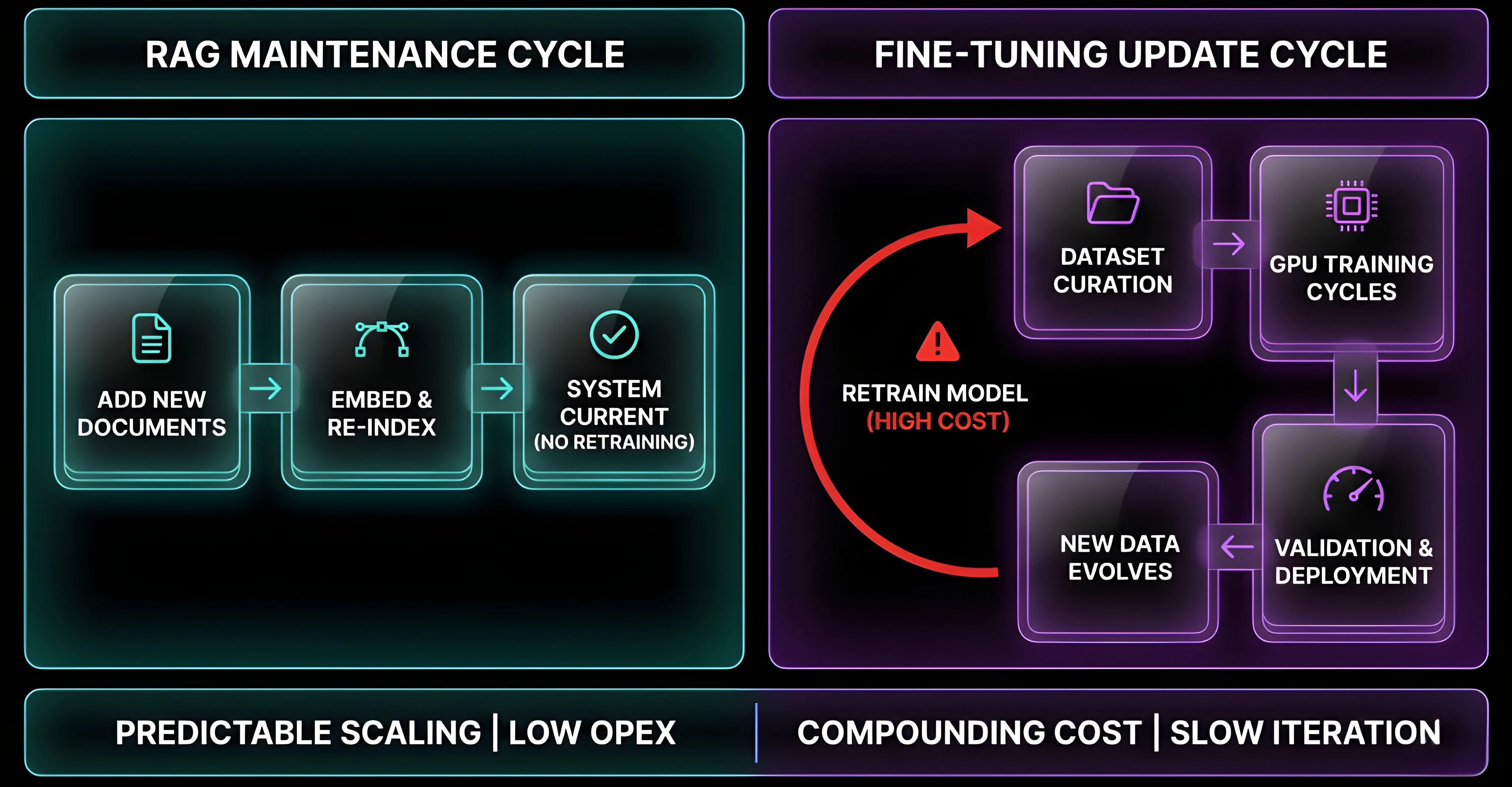
RAG simplifies that. You build the pipeline once by embedding the data, storing it and retrieving it when needed. From there, costs scale with usage and not experimentation, making it a strong foundation for AI cost optimization.
That’s what makes it a cost-effective AI implementation in environments where budgets are under scrutiny.
Your system stays current without retraining cycles
Fine-tuned models are static by design. The moment your internal data changes, your model is already behind. RAG systems do not have this limitation.
- Add new documents
- Re-index
- Done
No retraining. No redeployment.
In real enterprise environments, where data changes daily, this alone is enough to shift the decision.
Control does not get outsourced
Fine-tuning often pushes teams toward external pipelines or shared model environments.
RAG keeps your data where it belongs:
- Inside your infrastructure
- Behind your access controls
- Governed by your policies
This aligns directly with modern enterprise generative AI architecture, where data boundaries matter as much as performance, particularly in RAG enterprise AI systems.
Hallucinations become manageable
Let’s be precise.
No system fully eliminates hallucinations. But RAG changes the failure mode. Instead of generating from probability alone, the model generates from retrieved context.
That makes outputs:
Traceable | Verifiable | Grounded
Which is the only practical way to reduce AI hallucinations in production systems through effective grounding LLMs.
Where fine-tuning actually belongs and where it doesn’t
Fine-tuning has a role. It is just narrower than most teams assume.
Use it when you need to change how the model behaves:
- Domain-specific reasoning (legal, medical)
- Structured output consistency
- Tone, voice, or response style
Do not use it for:
- Injecting enterprise knowledge
- Keeping information updated
- Fixing hallucinations
That’s where budgets get burned and AI cost optimization breaks down.
Fine-tuning modifies the thinking of model. It does not fix what the model doesn’t know.
The cost discussion most teams avoid
Let’s break it down without abstractions.
Fine-tuning costs you:
- GPU-heavy training cycles
- Engineering time for dataset curation
- Repeated retraining as systems evolve
- Slower iteration cycles
RAG costs you:
- Embedding generation
- Vector database infrastructure
- Query-time compute
That’s it.
One grows with complexity. The other grows with usage.
For most organizations planning LLM deployment strategies 2026, that distinction determines long-term sustainability.
Speed = adapting fast.
Fine-tuning can slow teams in ways that are not obvious on the timeline.
Every update requires:
- Data adjustments
- Training cycles
- Validation
RAG separates knowledge from the model. Which means:
- Data can change independently
- Systems can adapt instantly
- Iteration doesn’t break the pipeline
That flexibility matters more than initial launch speed.
What a real enterprise setup looks like now
A working enterprise generative AI architecture is not model-centric anymore. It is layered, which reflects modern AI system design principles and incorporates a well-defined vector database architecture as a core foundation for scalable retrieval.
- Data ingestion pipelines bring in structured and unstructured data
- Vector databases handle semantic retrieval
- LLMs generate responses
- Access layers enforce permissions
RAG sits in the middle of this system. Fine-tuning sits outside it. That’s why one scales cleanly and the other adds friction.
The decision framework
No ambiguity. No overthinking
If you’re deciding between RAG vs fine-tuning, use this:
Need live, accurate, evolving data → RAG
Need controlled reasoning or tone → Fine-tuning
Need both → Start with RAG, then layer fine-tuning
In almost all enterprise cases, RAG comes first. Definitely not because it is trendy. This is because it solves the actual problem.
Where this fits in execution instead of theory
Architecture decisions do not matter unless they survive real-world usage.
To make this work:
- AI & Machine Learning Services define how retrieval and generation interact
- Custom Software integrates AI into workflows that actually drive outcomes
- Cloud Computing ensures the system scales without unpredictable cost spikes
This is where most projects succeed or fail. They fail not at the model level, but at the system level.
The direction is already clear
The industry is not debating this anymore.
What’s emerging?
- RAG-first architectures
- Vector databases as a standard layer
- Fine-tuning used selectively
All these because the problem has shifted. It is no longer about making models smarter. It is about making outputs reliable and consistently reduce AI hallucinations in production systems.
If you had to make the call today
If your system needs to answer questions based on real data, use RAG.
If it needs to reason differently or follow strict patterns, use fine-tuning.
If you try to handle both with a single approach, that usually leads to higher costs and weaker results.
Final take
Most enterprise fail. They fail because the system does not control what the model knows.
One should fix that layer first. Everything else becomes easier after that.
So, before you invest in training, ask, ‘Are you trying to improve intelligence or just make your system stop guessing?’
How Seaflux Helps You Get This Right
For teams looking to implement this the right way, Seaflux helps build scalable systems through custom AI solution design, AI integration services, and enterprise LLM solutions aligned with real business needs.
From rag implementation to custom AI development services, the focus is on reliable, production-ready AI without unnecessary complexity.
Schedule a callto see how Seaflux can help you deploy AI that actually works in real-world enterprise environments.

Hardik Dangodara
Business Development Manager