
At 10:02 AM… a customer upgrades their plan.
At 10:03 AM… your AI still recommends the old one.
Nothing is broken. But everything is already outdated.
This is how most enterprise AI systems fail. Not dramatically, but quietly. The model works. The logic is sound. The infrastructure is stable. Yet the output feels just slightly off.
The reason is simple. The system is not thinking in real time.
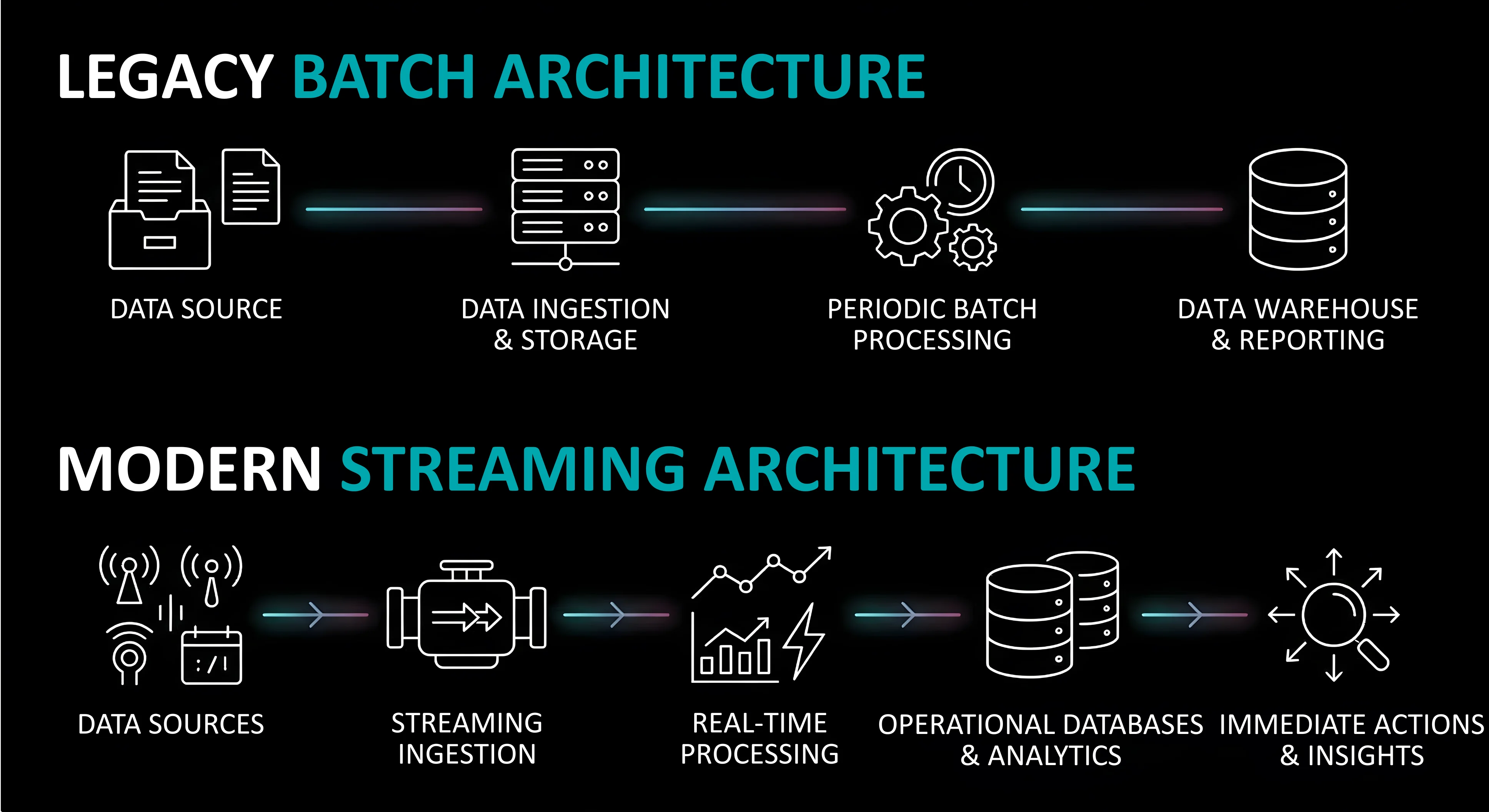
For years, AI systems have been built on batch pipelines, including traditional machine learning pipelines where data is collected, processed in cycles and then pushed into models. It made sense when decisions were slower and systems were less connected. That assumption no longer holds.
Business today operates on constant movement. Transactions, user behavior and system events are continuously updating, increasing overall data velocity across systems and requiring real-time data pipelines. When AI systems rely on delayed data, they do not just lag. They lose relevance. And this is where the gap appears:
AI insights are technically correct but contextually outdated.
Recommendations do not match current user behavior.
Operational decisions rely on signals that no longer reflect reality.
The issue is not intelligence. It is data velocity.
Real-time systems are often described as “fast.” That’s incomplete.
What matters is continuity. Data flowing without interruption from source systems into AI inference layers. No waiting, no batching, no periodic refresh, enabled by strong AI data integration across systems and streaming data pipelines.
Every event becomes part of the system’s awareness the moment it happens.
This is what enables live data LLM integration. The model is no longer reacting to stored data. It is operating on current business state.
That distinction changes everything.
Traditional pipelines move data in steps. Modern systems let it flow.
An enterprise streaming data architecture replaces scheduled movement with continuous streams of events, often built on an event-driven architecture where each event triggers immediate processing and downstream actions. Instead of processing data every few hours, systems process it the moment it is generated through streaming data pipelines.
This change does three things. Those are:
It removes latency between data and decision-making.
It allows systems to respond to events as they happen.
It ensures AI outputs reflect real-time context.
The result is not just faster responses but more accurate decisions.
To make continuous data flow possible, systems need a reliable event backbone. This is where Kafka for LLMs plays an important role.
Kafka captures streams of data from across the enterprise. This includes applications, APIs and databases. It distributes real time AI data pipelines to downstream services. But its real value lies in reliability.
Events are stored, replicated and can be replayed if needed. This means data is never lost. Even if parts of the system fail. AI systems can always reconstruct context from the stream.
For organizations building real-time AI, Kafka becomes less of a tool and more of an infrastructure layer powering streaming data pipelines and enabling scalable AI for business operations.
Streaming data is only useful if it can be processed instantly.
This is where continuous AI data ingestion comes in. Instead of waiting for data to accumulate, AI data ingestion systems process events as they arrive within a streaming data architecture. Validation, transformation and enrichment happen in motion.
There is no delay between ingestion and availability, significantly reducing pipeline latency.
This removes one of the biggest hidden bottlenecks in AI systems. The gap between data arrival and data usability.
For engineering teams, this requires a shift in thinking. Pipelines are no longer batch jobs. They are always-on systems, evolving beyond static machine learning pipelines into continuous data processing flows.
LLMs are powerful but they are inherently static. Their knowledge does not update unless explicitly fed new context.
Traditional RAG improves this by retrieving relevant data. But in many systems, that data is still updated periodically.
Streaming RAG takes it further and is often referred to as streaming RAG in modern AI architectures.
As new data flows through the system via real-time data pipelines within a streaming data architecture, it is immediately embedded, indexed and made available for retrieval. This means the model’s context evolves continuously. The impact is significant.
AI systems can now respond based on what is happening right now and not what happened hours ago. Whether its financial activity or customer interactions or operational signals, the model is always working with fresh context.
This is what makes AI operationally reliable.
Stale outputs rarely trigger alerts. They do not cause system crashes. Instead, they slowly erode confidence.
Users begin to question recommendations. Teams start double-checking outputs. Over time, adoption drops.
Preventing this requires more than better models. It requires a system where data freshness is guaranteed through a well-designed streaming data architecture and strong data pipelines for AI.
In mature architectures, freshness is treated as a measurable metric. Systems are designed to minimize the time between data generation and AI consumption, often supported by a real-time analytics platform that continuously evaluates and surfaces live insights.
Anything less introduces risk.
Real-time systems operate under constant load. Data never stops flowing, which means failures must be handled without interruption.
Pipeline resilience becomes critical.
A strong system is built to absorb failures. It redistributes load during spikes and recovers automatically from disruptions. It makes sure that no data is permanently lost. This is not just about uptime. It is about consistency under pressure, supported by a resilient AI data architecture.
Without resilience, real-time systems become fragile. With it, they become dependable.
As data moves faster, it also becomes harder to control.
Security has to be built into every layer of a streaming architecture. This includes data in transit, data at rest and data in use. Access must be tightly managed and sensitive information must be protected even within internal systems.
For enterprises, live data LLM integration must be secure by design to support trusted AI for business operations.
This includes encryption, access control and full auditability of how data flows through the system. Particularly in regulated environments. This is not optional. It is mandatory.
The way usage grows… so does data volume. Real-time systems must scale without introducing latency or instability.
This requires distributed infrastructure capable of supporting high-throughput streaming data pipelines. That infrastructure can handle high throughput. It must maintain performance while doing so. Cloud Computing Services enable this by providing elastic scaling, allowing systems to expand and contract based on demand.
Scaling is not just about handling more data. It is about maintaining performance consistency at any scale, enabled by a scalable AI data architecture.
The biggest shift real-time pipelines enable is not technical. It is operational.
AI moves from being a source of insights to a driver of actions.
Decisions are made faster. Systems respond automatically. Processes become dynamic instead of reactive, powered by real-time streaming data pipelines within an AI data architecture.
This is where the real business value emerges.
Delivering this level of capability requires alignment across multiple domains.
Data Engineering Services design and maintain streaming pipelines.
AI and Machine Learning Development integrates LLMs with live data.
Custom Software Development builds systems tailored to specific workflows.
Cloud Computing Services ensure scalability and reliability.
When come together… these capabilities create systems that are intelligent. But along with that they are continuously aware.
AI does not fall behind because it lacks capability.
It falls behind because it is fed yesterday’s data.
The organizations that solve this will not just have better AI.
They will have faster decisions and sharper insights. Their systems will move at the pace of their business, powered by strong data pipelines for AI.
At Seaflux, we specialize in building real-time AI systems powered by modern data architectures. Our data engineering services and data pipeline development services ensure seamless, high-performance data flow across your business.
We deliver scalable AI solutions for enterprises, along with LLM integration services that connect models with live data, helping organizations make faster, smarter, and more reliable decisions.
Schedule a meeting with us to explore how we can help you build and scale real-time AI systems tailored to your business needs.

Business Development Manager