Broken ETL to Agentic Data Engineering: The Future of Data Orchestration
POV: It’s Monday morning.
Your dashboard is off. Not broken, just off.
Numbers do not match last week, a report is delayed and somewhere in the pipeline, something silently failed. The team starts tracing logs, patching scripts, rerunning jobs. By the time it is fixed, the insight is late and the confidence is gone.
This is not a rare incident. It is how most data systems operate today and why conversations around data engineering trends are becoming more urgent.

The Problem with “Working” Pipelines
Traditional ETL pipelines and data orchestration systems were built for a different era. Batch processing, predictable schemas, controlled data sources.
They were NEVER designed for:
- Real-time decision systems and real-time data processing
- Continuously evolving data sources
- AI models that depend on fresh, reliable inputs
- LLM-powered applications that break with inconsistent context
Yet most organizations are still running variations of the same pipelines. Just with more tools layered on top. The result is fragile complexity.
Pipelines technically “work,” but they require constant attention. Engineers spend more time maintaining flows than improving them. Every schema change becomes a fire drill. Every failure requires manual intervention, often requiring manual data quality monitoring and ongoing data pipeline optimization.
This is where the time where change begins from maintaining pipelines to rethinking them, including how data orchestration is approached in the era of AI in data engineering and agentic data engineering, driven further by agentic AI in data engineering.
Why Automation was not Enough
Automation helped but only to a point.
Scheduling jobs, retrying failures and triggering alerts. All these reduced manual effort. But they did not remove the underlying problem.
Automation follows predefined rules. It executes what it is told. It does not:
- Understand why a pipeline failed
- Adapt to unexpected schema changes
- Optimize transformations dynamically
- Decide how to fix issues without human input
So while automation reduced effort, it did not reduce dependency.
Teams still needed engineers to step in whenever something broke. And as systems scaled, those interruptions became more frequent. This is the ceiling of traditional AI-driven ETL when it is still built on static logic.
Enter Agentic Data Pipelines
The change happening in data engineering 2026 is not only about better tools. It is also about a different model altogether.
Agentic pipelines introduce autonomous systems that execute workflows. And along with that they reason about them. This is the difference between automation and agency.
An automated pipeline runs a script. An agentic pipeline understands context and detects anomalies. It even takes corrective action in real time, making it well-suited for real-time data processing environments and modern cloud data pipelines, and forming the foundation of agentic data engineering and self-healing data pipelines.
This includes:
- Identifying schema drift and adapting transformations automatically
- Detecting data quality issues before they propagate downstream
- Optimizing queries based on usage patterns and enabling continuous data pipeline optimization
- Rerouting workflows when dependencies fail
- Learning from past failures to prevent future ones
These are not pre-coded responses. They are decisions made by systems designed to interpret data behavior. This is what defines agentic data pipelines and the growing impact of AI in data engineering.
|
Free Download
Is Your Data Stack Ready for Agentic AI?
A 25-point self-assessment for CTOs and data engineering leads evaluating the shift from static ETL to agentic, self-healing data systems.
|
From Reactive Fixes to Self-Healing Systems

One of the most significant changes is the move toward self-healing data workflows.
In traditional setups, failure detection triggers alerts. In agentic systems, failure detection triggers resolution.
Instead of notifying an engineer that something broke, the system:
- Diagnoses the issue
- Applies a fix or workaround
- Validates the output
- Logs the action for traceability
All without interrupting the flow, while maintaining continuous data quality monitoring and enabling self-healing data pipelines.
This does not remove human oversight. It changes the role of engineers from responders to supervisors. They focus on improving systems and not constantly fixing them, which is a core principle of agentic data engineering.
We've helped teams cut pipeline failure response time from hours to minutes. Curious what that looks like for your stack?
See how →The Rise of Autonomous Data Orchestration
Sequencing tasks has always been important to orchestration. It includes what runs when and in what order. But modern systems require adaptability along with sequencing.
Autonomous data orchestration adds intelligence to this layer. Rather than relying on fixed DAGs, orchestration becomes dynamic as in:
- Pipelines adjust execution paths based on real-time conditions
- Dependencies are managed contextually rather than statically
- Resource allocation adapts to workload demands
- Failures trigger alternative execution strategies
This is especially important in environments where data sources are unpredictable. They are often continuously evolving. The system does not just follow a plan. It adjusts the plan.
Generative AI is changing Data Ingestion
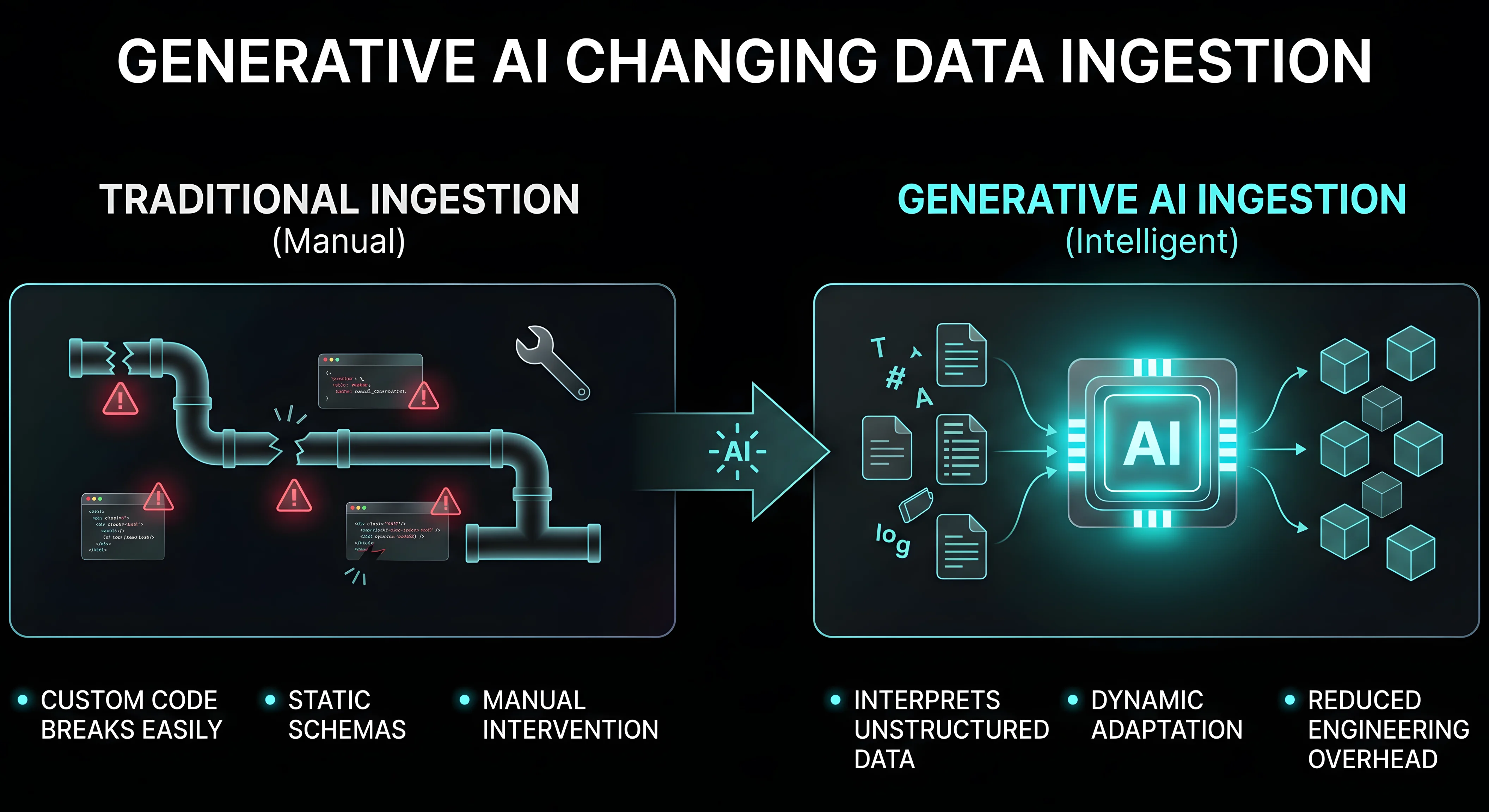
One of the most overlooked challenges in data engineering is ingestion.
Pulling data from APIs, documents, logs and third-party systems often requires custom parsing logic that breaks easily. This is the place where generative AI for data ingestion is making a difference and accelerating data ingestion automation.
AI models can:
- Interpret semi-structured and unstructured data
- Extract relevant fields dynamically
- Adapt to format changes without rewriting code
- Understand context across different data sources
This reduces the need for constant updates to ingestion pipelines.
More importantly, it allows organizations to work with a wider variety of data without increasing engineering overhead, strengthening modern AI data engineering capabilities and advancing agentic AI in data engineering.
Building AI-Ready Data Foundations
The rise of LLMs and AI-driven applications has changed what “good data infrastructure” looks like. It’s no longer enough for data to be accurate. It needs to be:
- Timely
- Contextually rich
- Consistently structured
- Easily accessible across systems
Agentic pipelines and intelligent data orchestration allow this by ensuring that data remains reliable without constant manual intervention. This is what it means to build an AI-ready foundation. Not just storing data but maintaining its quality and usability in real time through AI in data engineering and scalable cloud data pipelines.
Reducing the Unseen Cost of Data Maintenance
One of the biggest challenges CTOs face is not building pipelines. It is maintaining them.
Legacy ETL systems come with hidden costs:
- Continuous monitoring
- Frequent debugging cycles
- Engineering time spent on non-core work
- Delays caused by pipeline failures
These costs do not always show up in budgets but they impact delivery speed and team efficiency. Agentic systems reduce these costs by handling routine issues autonomously and improving data pipeline optimization. Instead of scaling teams to manage complexity, organizations scale systems to handle it.
Where Seaflux fits into this Shift
Transitioning from traditional ETL to agentic pipelines is not just a tooling upgrade. It is an architectural shift. Seaflux enables this through data engineering services and platform engineering services, helping organizations move from fragile, script-based pipelines to adaptive, intelligent systems.
With generative AI development services and custom AI solutions, agentic capabilities are embedded directly into pipelines, powered by agentic AI workflows that enable real-time decision-making, anomaly detection, and continuous optimization. As a cloud solution provider, Seaflux ensures these systems scale efficiently while integrating flexible data ingestion solutions to handle evolving data sources.
The focus is on delivering custom software development services that go beyond building pipelines to creating systems that can maintain and improve themselves.
The Strategic Advantage
Organizations that adopt agentic pipelines and advanced data orchestration gain more than operational efficiency.
They gain:
- Faster access to reliable data
- Reduced dependency on manual intervention
- More predictable system behavior
- Stronger foundations for AI-driven applications
This creates a compounding advantage.
Good data makes better decisions possible. Good systems make execution faster. And over time, that gap becomes difficult to close, especially for organizations investing in AI data engineering.
Last Thought
Data engineering is no longer just about moving data. It is about what happens after it gets there. It is also about ensuring that data remains usable, reliable and responsive. This matters in an environment that is constantly changing.
Traditional ETL pipelines were built for stability. Modern systems require adaptability.
Agentic pipelines bring that adaptability by introducing systems that can think, respond and improve continuously. The change is already underway as AI data engineering reshapes the landscape and accelerates agentic data engineering, defining the future of ETL.
Still patching the same pipeline failures every week?
"It comes down to whether your data stack can handle it? Or still waiting for someone to fix the next pipeline failure."
Most teams waste 30–40% of engineering time on maintenance. Let's audit your current data stack and show you what an agentic setup would actually look like for your use case.

Krunal Bhimani
Business Development Executive