
Businesses are now operating 24/7 to meet customer demands. And it cannot afford to have interruptions in its operations at the highest demand time. Even the slightest of interruptions can lead to the loss of customer trust and create dissatisfied customers. Businesses don't want this to happen, as rightly said by Michael LeBoeuf – “A satisfied customer is the best business strategy of all.” To avoid such a scenario, a fault tolerant infrastructure is an ideal solution that reduces the losses to the businesses.
In this blog, we are going to touch base on what is Fault Tolerance and High Availability (HA), compare High Availability vs Fault Tolerance, and define the components that are used to develop a successful Fault Tolerance infrastructure. In our next blog, we will get our hands dirty to implement the Fault Tolerance infrastructure with a step-by-step guide.
Fault Tolerance means the ability of a system to function flawlessly even if one or more components have failed to perform or not working up to the mark. It is obtained by switching to a redundant system, that is being implemented at times like this to provide uninterrupted service. A Fault Tolerant infrastructure practically means 100% uptime. However, it comes at a very high cost, and businesses use it for mission-critical workloads.
Whereas, a High Availability system may have some interruptions. To represent the high availability, a sequence of 9s is utilized that denotes the level of availability.
| AWS Availability Levels | Downtime in a Year |
| 99.9% Three-nines availability | 8 hours and 46 minutes of downtime |
| 99.99% Four-nines availability | 52 minutes and 36 seconds of downtime |
| 99.999% Five-nines availability | 5 minutes and 15 seconds of downtime |
| 100% availability [Fault Tolerance] | 0 minutes downtime |
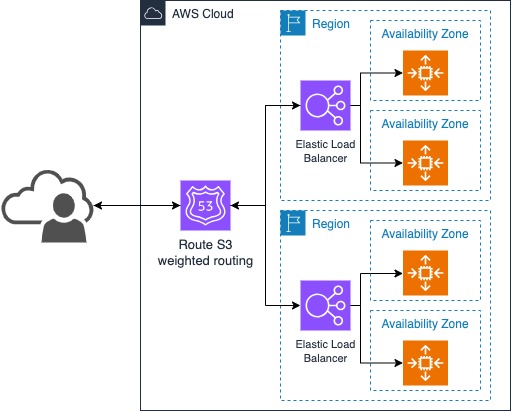
The following features are important to know before you implement a fault tolerant infrastructure:
AWS hosts its IT infrastructure systems in different geographical locations called AWS Region, which has multiple, physically apart, AWS Availability Zones (AZs). These AZs share no service-critical components and operate to provide low latency, inexpensive network connectivity to other Availability Zones in the same region as well. Hence, they have high availability ranging from 99.9% to 99.999%. Running independent application stacks in more than one AZ within the same or different Region is important for mission critical workloads to ensure 100% uptime.
This step is to safeguard the application against downtime and have high availability.
AWS recommends the following guidelines:
Various service & feature mixes of AWS can be utilized to implement the fault tolerance in multiple AWS Availability Zones. Some of the key services can be AWS Route 53, AWS Lambda, EC2, AWS RDS, and more. We will be discussing them in the forthcoming topic.
A very crucial part of implementing fault tolerance infrastructure is the 'Monitoring & Managing' of the infrastructure. So in case of any failure, the workload can be shifted to the redundant AWS Region. Consider the following aspects for monitoring and managing:
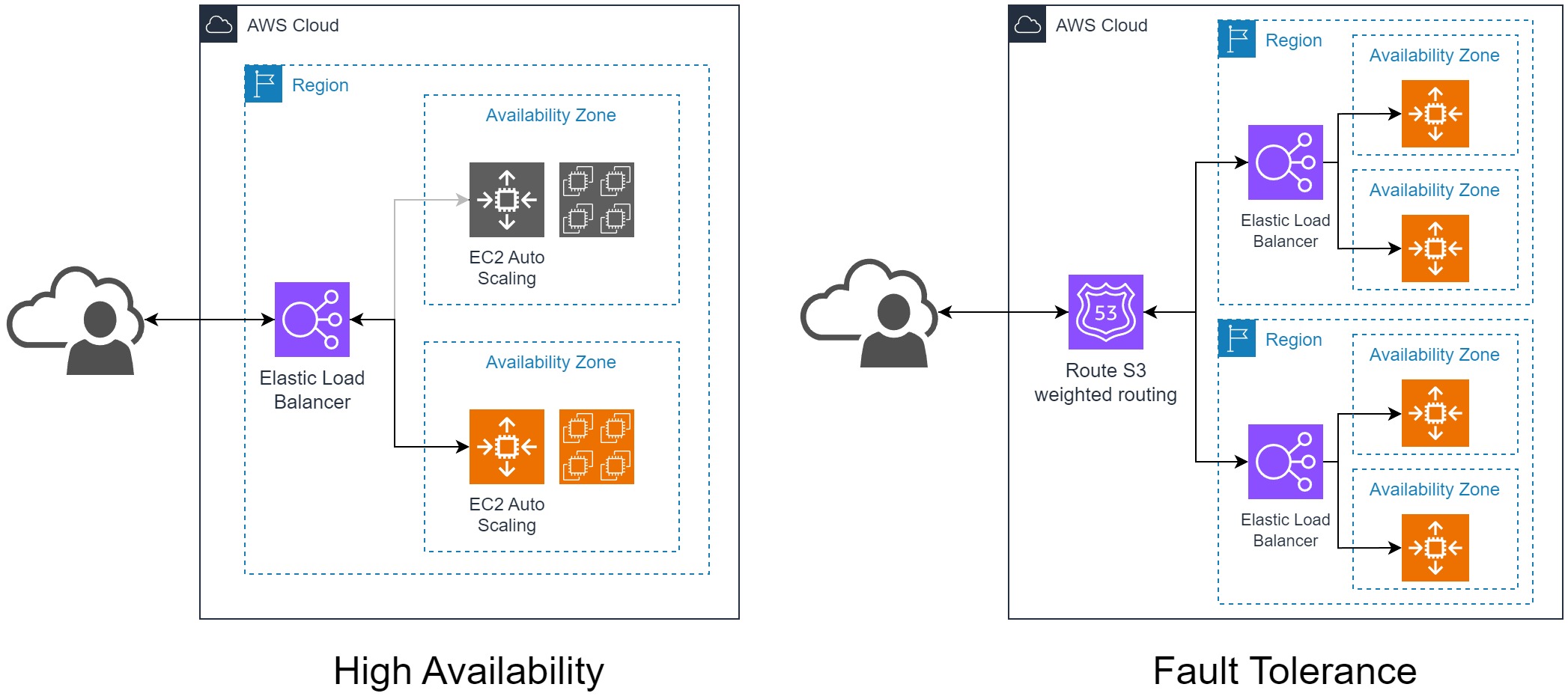
A fault-tolerant infrastructure means 100% available with zero downtime. This system is closer to a disaster recovery system. A fault tolerant system may come at a higher cost, however, it provides a 100% uptime guarantee for mission critical workloads. A High Availability system costs much less and provides high availability ranging from Three 9s to Five 9s. Businesses that can afford downtime for their customers may prefer a High Availability infrastructure instead of paying a much higher cost for fault tolerance. However, a mission-critical workload, like a nation's security or scientific experiment involving tons of money, can not afford a single second of downtime that could jeopardize their goal.
Below is an architectural diagram depicting the High Availability vs Fault Tolerant system.
Let us talk about deploying a fault tolerance system in AWS. Here, we will talk about the AWS services used to successfully deploy a fault tolerance infrastructure. As for the 'How to Deply' part, we will cover it in our next blog, where we will go through a step-by-step guide with samples to showcase the deployment in AWS.
Most businesses require highly available infrastructure with minimal downtime in the ranges of Three 9s to Five 9s. However, a few mission critical projects need the fault tolerance system to support their projects at all times. We have covered the basics of Fault Tolerance and High Availability in this blog, and to know how to deploy it in AWS, stay tuned for our next blog. AWS being one of the leading cloud providers, is quite reliable and available worldwide.
We at Seaflux are your dedicated partners in the ever-evolving landscape of Cloud Computing. Whether you're contemplating a seamless cloud migration, exploring the possibilities of Kubernetes deployment, or harnessing the power of AWS serverless architecture, Seaflux is here to lead the way.
Have specific questions or ambitious projects in mind? Let's discuss! Schedule a meeting with us here, and let Seaflux be your trusted companion in unlocking the potential of cloud innovation. Your journey to a more agile and scalable future starts with us.

Senior Marketing Executive