3 ways to build a movie recommendation system using Scikit Learn
Watching Spiderman 2 on an OTT platform, and as soon as you finish watching it, you receive the suggestion of playing Spiderman 3. Ever wondered how the service provider knows which movies or TV shows to recommend? It is powered by an OTT platform recommendation system, which understands what a user wants. Let us see what a recommendation system is and how to develop one using Scikit-learn.
In this blog, we will be covering the following topics:
- Why are recommendation engines so important?
- What are their different types?
- How do we implement them?
Scikit learn code for each type of recommendation system has been provided for easy and better understanding. We'll take an example of a movie recommendation problem statement.
A recommendation engine recommends the most relevant product/service to the users by filtering and analyzing the data using different algorithms. Recommendation engines are the selling point of almost all fortune 500 B2C companies. FAANG (Facebook, Amazon, Apple, Netflix, Google) are considered to be the best of all the recommendation engines.
Dataset source: link
Importance of recommendation systems :
As mentioned above, the recommendation engine recommends items to the users with the help of data accumulated, either from the users or from the item description. This helps to provide users a personalized recommendation which, in turn, increases the quality of the user experience and enhances their engagement. It also helps sellers with upselling / cross-selling and more traffic to the website. This benefits every stakeholder by making the shopping experience, or watching the movie in our case, more enjoyable and provides the most value to the users.
Types of recommendation systems
There are multiple types of recommendation systems, out of which we are going to discuss Collaborative filtering, Content based recommendation systems, and Hybrid recommendation systems. These systems are heavily used all across the globe because they are commercially and computationally cost-effective.
Collaborative Filtering
The systems based on this filtering algorithm need the user data (previous ratings, reviews, transactions) to recommend any product/service.
This system approaches the problem at hand in 2 basic methods:
- User-User collaborative filtering
- Item-Item collaborative filtering
In the User-User filtering algorithm, a particular user is compared with a pool of users and then recommended the products/services liked by the user with the most similar purchase patterns and product reviews. Whereas, in the Item-Item filtering algorithm, items/services with similar ratings and review sentiments are paired and then recommended to any user who shows interest in a similar item/service.
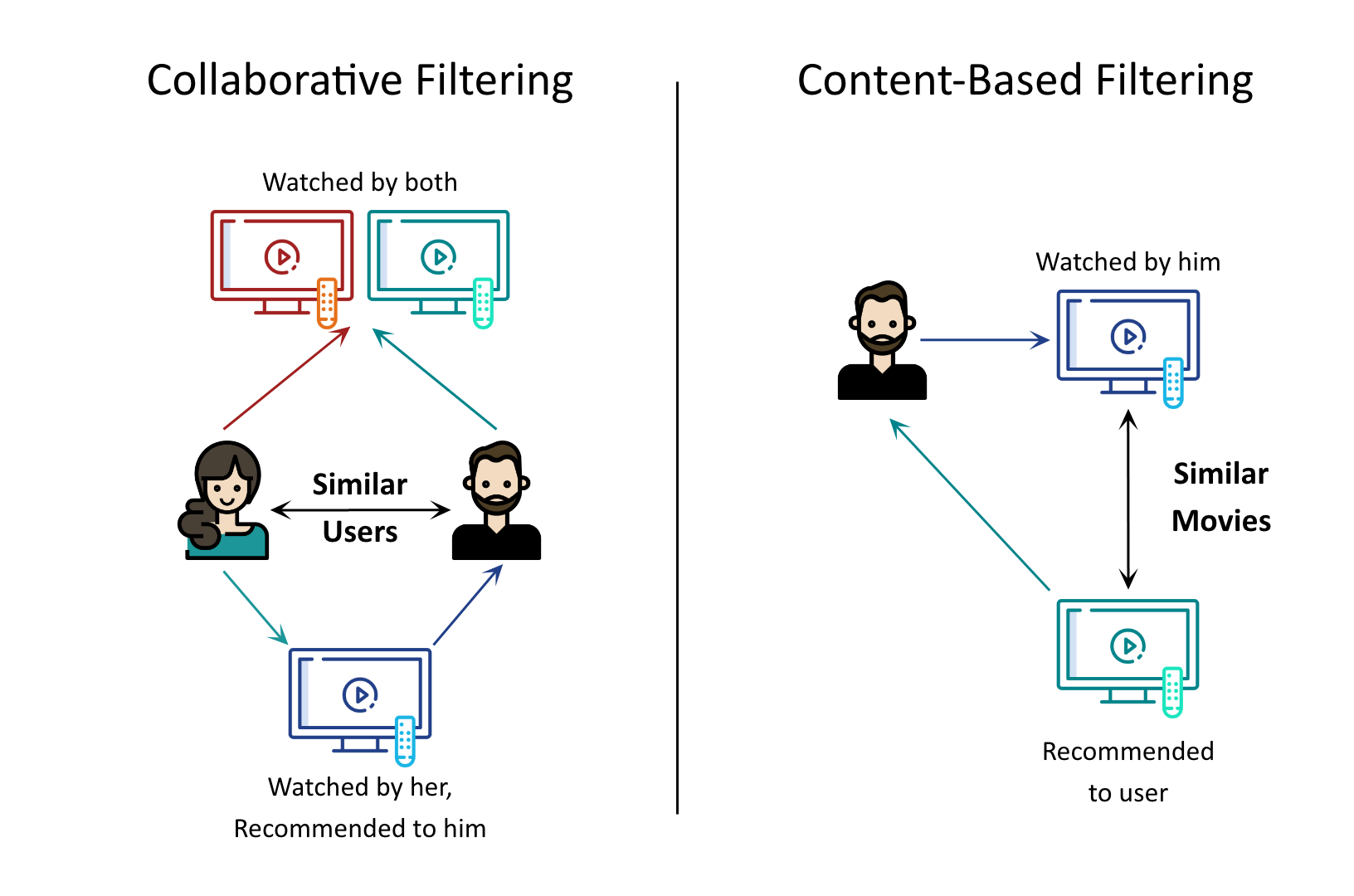
Content based recommendation systems :
These systems do not require user data to recommend any product/service. Instead, they use AI for recommendation systems to find similarities between product descriptions. A Scikit learn recommendation system can be used here to build a model based on item features. For eg: As we discussed, if you are watching Spiderman - 2, which is an action movie, the movie recommendation system would suggest Spiderman - 3, whereas the movie, The Avengers (a much famous action movie) would not be the recommendation.
These types of recommendation systems are used for upselling and used to improve user experience and increase sales of the companies.
Hybrid recommendation systems
These systems require the deployment of multiple types of recommendation engines for a single recommendation. The rule is simple, if the data fed into the AI model isn’t enough for a stand-alone algorithm to recommend properly, we will combine the power of multiple weak recommendation systems to decrease our false positive rate and provide a consistent recommendation. This ensures that out of 5 recommendations given to a user, at least 2-3 are accurate. This is a statistical approach, however, technically we will assign a particular weight to every recommendation system for more accurate results (the better system has more say in the recommendation of product/service).

Which one to choose for an OTT/eCommerce platform?
The same recommendation system can be used for eCommerce platforms as well and an accurate engine is one of the few things which differentiates a great platform from a generic one. It helps to personalize the user experience, creates an equal market through upselling, and increases the platform's overall reputation.
When in an early stage, the platform might not have user data. However, it does have the products/services data fed into the system by the merchants. We can train our AI models on this data and develop a Content based recommendation system as discussed above. Using Natural Language Processing, our system finds the relation between two different products of the same brand and recommends the other product to the user. This upselling increases the sale of different products from the same brand. We can generate data out of this, such as the purchase patterns of the user.
When the platform scales up and the number of users increases, the Content based recommendation system might get inefficient due to the rise in the variety of products. We must combine multiple types of weak recommendation systems to develop a considerably accurate recommendation system. These hybrid systems are built using statistical approaches and vary from time to time, domain to domain. It may seem a little difficult, however, it is the most convenient and cost-effective approach among all the other possible solutions.
When the customer base gets huge, and when we need to deal with big data, then we use Collaborative filtering. At this point, the AI algorithm demands the user data, for eg :
- purchase history
- purchase patterns
- previous transactions
- cart details
- product ratings
- product reviews
- merchant ratings
- merchant reviews
- platform sentiment / churn rate
Conclusion:
Hence, according to the scale of the eCommerce platform and the customer base, we can decide which AI algorithms, such as those implemented in a Scikit learn recommendation system, would be the best fit for the recommendations given by the platform. Analyze yourself and develop your own Scikit learn recommendation system for more personalized offerings to your products/services using AI/ML.
We, at Seaflux, are AI & Machine Learning enthusiasts who are helping enterprises worldwide and recognized as one of the top 30 Charlotte software companies. Have a query or want to discuss AI or Machine Learning projects? Schedule a meeting with us here, we'll be happy to talk to you!

Jay Mehta
Director of Engineering