Credit Card Fraud Detection: Solve the FinTech puzzle with AI
Due to the recent advancement in technology, more and more people are using credit cards. And not only people but every organization, from small-sized businesses to big enterprises, are using credit cards as their mode of payment. And this advancement is ultimately breeding to scams like Credit Card Fraud as the other side of the coin.
Credit card fraud detection is one of the biggest challenges faced by many government agencies and big companies, with an enormous amount of money involved in these transactions. So, it needs a robust fraud detection solution to deal with the loss of billions of dollars. Effective credit card fraud prevention requires advanced technologies that can identify and mitigate fraudulent activities before they impact the financial system.
One promising approach is using Machine Learning for fraud detection with Python, which can instantly recognize fraudulent transactions and potentially save substantial amounts of money. However, there are several challenges faced by service providers when developing such solutions in finance problems.
In this blog, we will be looking at the problem that will arise due to the highly imbalanced data, their probable solution, and the step-by-step coding method for credit fraud detection. We will be using the Kaggle dataset in Google Colab for the fraud detection solution with supervised learning using AI & Machine Learning.
Have a look at some of the problems:
- The model training in supervised learning requires good quality data. However, due to the privacy policies of the banks in place, they cannot share the data in its direct form for training which raises the issue of Data Availability.
- Even though we gain a quality dataset, not violating any of the privacy policies, the dataset would be Highly Imbalanced and thus making it tough to identify the fraudulent transactions from the authentic ones.
- Also, the AI model for credit card fraud detection must be fast enough to identify a fraudulent transaction, which can be a challenge since enormous data is processed every day.
- Last but not least, scammers may invent new techniques in which the model cannot detect these fraudulent transactions.
Some solutions to tackle these challenges:
- To deal with the data availability issue, the Dimensionality of the Dataset can be reduced. Methods like LDA(Linear discriminant analysis), PCA(Principal Component Analysis), etc., can be used in achieving the said target.
- A highly imbalanced dataset for credit card fraud detection can be converted into a balanced dataset using resampling methods like class weights, Random Oversampling or Undersampling, a combination of SMOTE and Tomek Links, etc.
- The model used must be simple and fast enough to handle the enormous data and can be at the cost of minimal accuracy.
- If the built model is simple enough, we can apply changes with some tweaks and deploy a whole new model to avoid any new techniques used by scammers against the model.
METHOD AND CODE:
First of all, choose a coding platform to code the model. We have used Google Colab as the platform, which is well suited for machine learning. However, there is no restriction in using Kaggle or any other coding platform of your convenience. You can also use Jupyter Notebook to code on your local machine rather than using cloud-based platforms.
Installing Important Dependencies:
Listed below are all the dependencies needed:

The above code will import all the libraries we will use if we run this code cell in Google Colab or Kaggle. However, you will have to install these libraries separately in your system if you are working on your local machine, after which the above code cell will import these libraries.
Dataset:
The dataset used here is taken from the Kaggle website and can be downloaded by clicking on the download button on the top-right corner of the website here.
After downloading the Kaggle dataset, use the below cell to load the data into the ‘data’ variable by specifying the path location of the dataset.

NOTE: The path provided in parentheses must be the same as the path location of your Kaggle dataset. If you use Google Colab, you have two options: either upload the dataset or mount your Google Drive to fetch the data.

Understanding the data:
Let us take a look at our data:
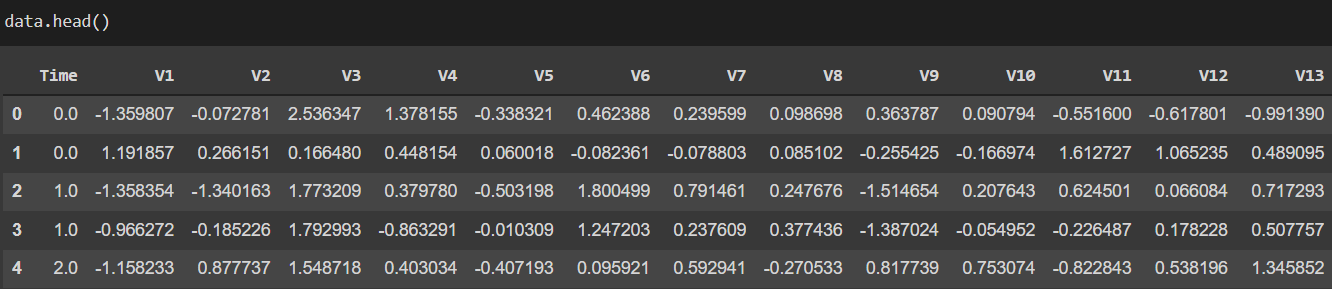

The dataset contains 28 original feature columns, which are replaced with V1, V2, …, V28 using PCA transformation for the privacy of the user. The other three additional columns are time, amount, and class.
Now, let us observe what are the features of the data by executing the given code.
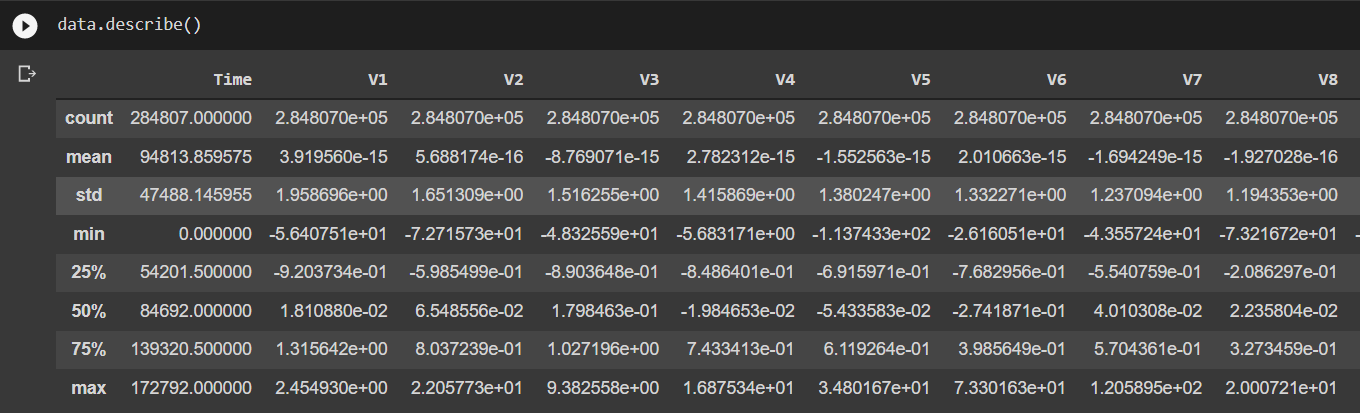
We can see features like total count, mean, standard deviation, minimum, maximum, etc., for all the columns.
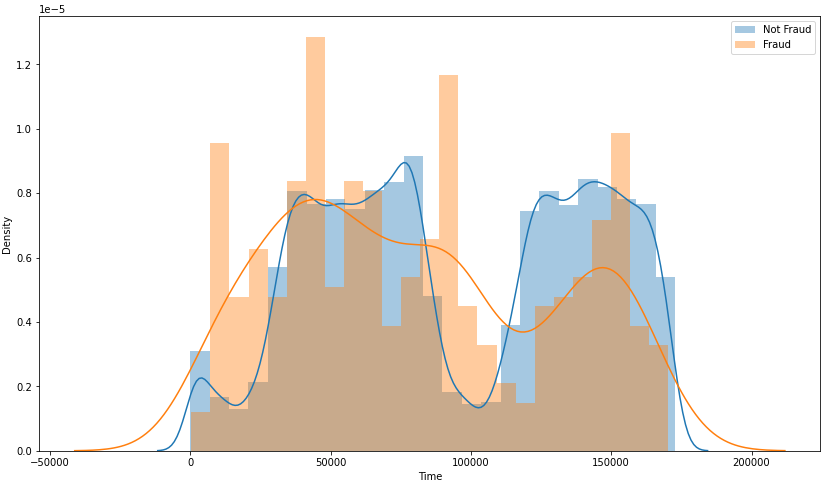
The time column contains the time elapsed between the first transaction and the current one. To obtain more knowledge, visualize it using the Seaborn library. We can see here that the density of fraud transactions is usually more at night when compared to the authentic ones, which are less by looking at the graph as shown below.

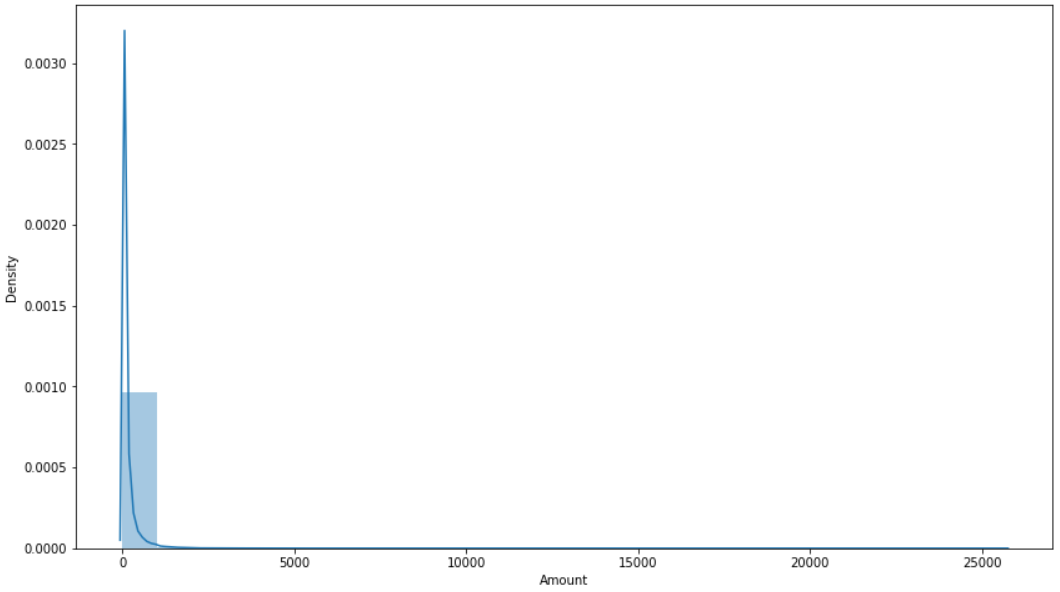
We can similarly visualize the amount column as well. Here, we can see that the density of low amounts is the highest, and only some of them are high amount transactions. The same can also be inferred from observing the mean value, which is only $88, and the highest amount is $25691, indicating that the distribution is heavily right-skewed.

Class Distribution:
Now let’s see the total number of fraudulent and non-fraudulent transactions and compare them.
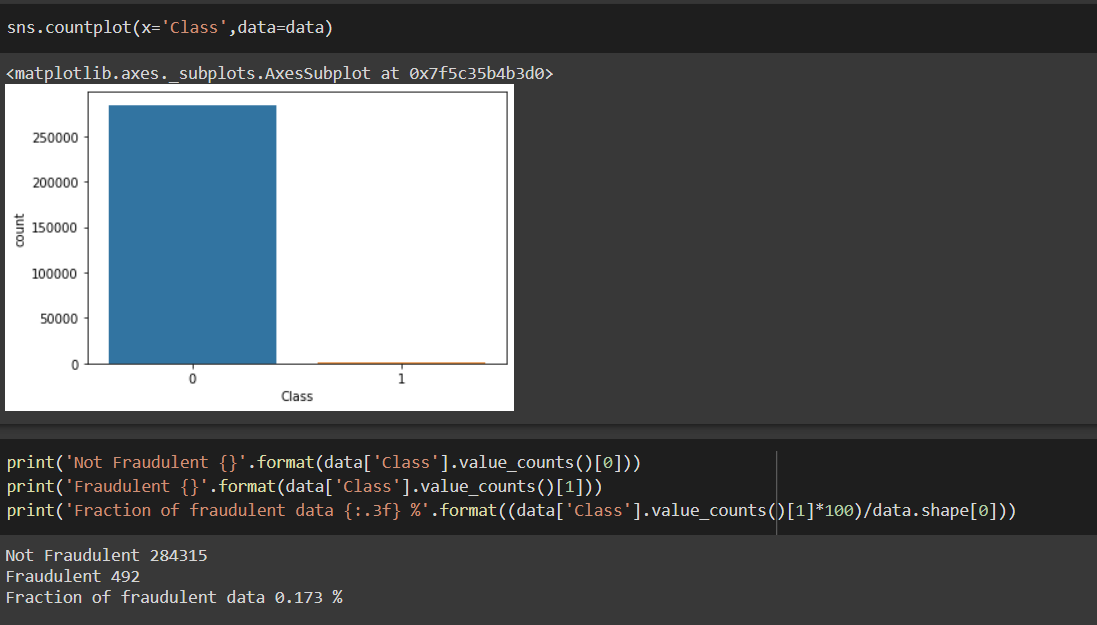
As we can see, only 0.173% of the whole data are fraudulent cases which are less to train our model and the reason why we cannot solely depend on accuracy as our only metric for the result. We must use some resampling techniques to get our model to learn more about fraudulent cases.
Using the correlation matrix, we can get some insight into what is the correlation between all the features. This correlation will help us to know which features we can use for prediction.
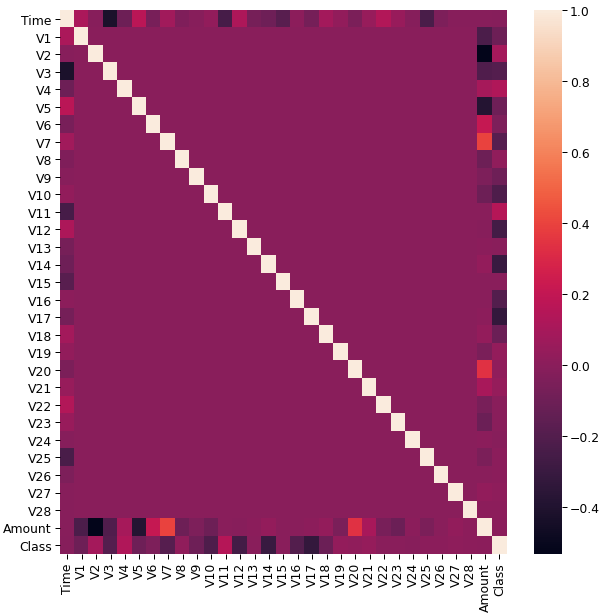

Now, you may ask why do we need fraud analytics if only a small amount of fraudulent transactions occur. Well, to put it simply, fraudulent transactions happen in billions of dollars every year, and if we save only 0.1% of these transactions will mean we have saved millions of dollars. This is not a small amount considering that it can change the lives of many people.
Outlier Removal using IQR(Interquartile Range):
Outlier removal can be a difficult task, as the trade-off between reducing the number of transactions and the amount of information left is not easily solvable and it depends on the amount of data as well. This method says that the data outside the 1.5 times IQR is usually considered as outliers. However, if we take 1.5*IQR, then it decreases our dataset size drastically, and hence we have used 1*IQR instead of 1.5*IQR to balance the trade-off.


And now the amount of data left is:
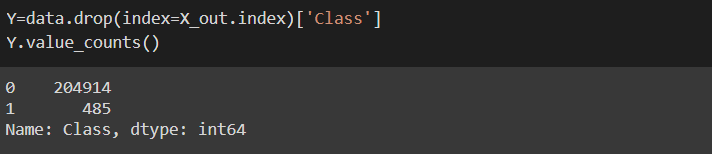
Splitting the Dataset into Training and Testing data:
In order to make our model learn, we need to split the Kaggle dataset that we have downloaded into two parts viz. training dataset and testing dataset. The training dataset will train the model with the data such that when the testing dataset is being provided as the input, the AI model can analyze and give the desired output.
Scikit Learn library provides such preinstalled tool to split the dataset, the code cell for the same is as below:
‘train_test_split’ from Scikit Learn library is used here.

Resampling data using SMOTE-Tomek Links:
By only using Random Undersampling or Oversampling, it causes a reduction in data size and increment in data size, which then increases training time. And since our model needs to be simple and fast enough, we have used a combination of SMOTE, which oversamples the minority class, and Tomek Links, which removes the examples from the majority class, to produce a balanced distribution.
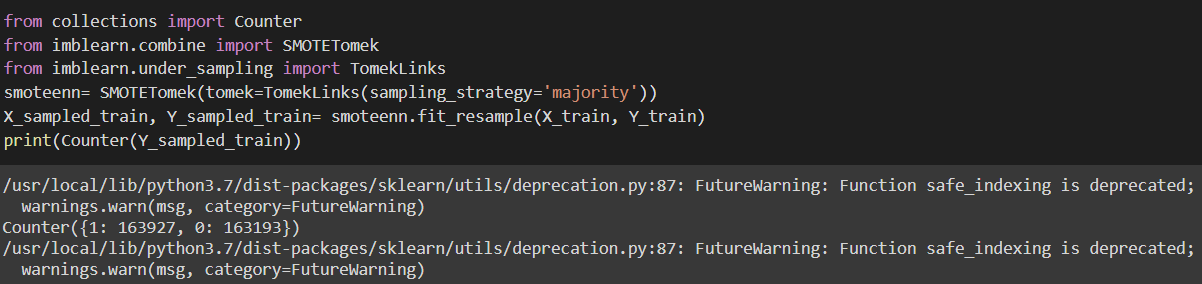
As we can see the class distribution is very balanced right now.
Building Classifier models to predict the results:
Decision Tree Classifier:
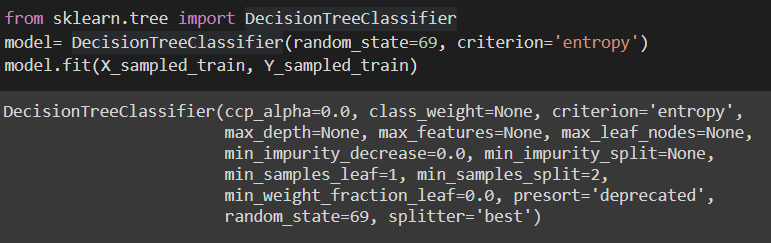
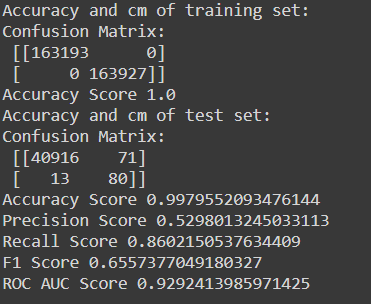
As we can see in the decision tree classifier, there is a good amount of accuracy and recall, however, the precision score is not satisfactory. And this can also be inferred from the confusion matrix where false-positive transactions are more than they should be.
Random Forest Classifier:
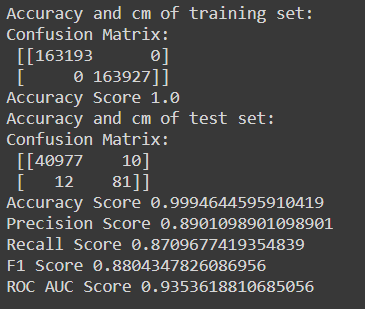
As we can see, the random forest classifier has accuracy, precision, and recall values that are quite a satisfactory one with an F1 score of 0.88 and ROC AUC score of 0.935.
Conclusion:
At last, we can witness that by using machine learning for fraud detection and fraud detection with AI, we can save people’s money from many fraudulent transactions easily and very quickly. Moreover, the privacy of the customers has been kept intact, and the problem of the imbalanced dataset is also resolved by analyzing the fraud analytics. So all the challenges discussed above are almost dealt with using the supervised learning model of machine learning.
Also, for more accurate results, you can amend these methods and include many techniques like:
- Hyperparameter Tuning: Hyperparameter can be tuned with the help of GridSearchCV or RandomizedSearchCV to improve results.
- Use Feature Scaling for other algorithms like Logistic Regression, XGBoost, SVM, etc.FI, which may perform better than Random Forest.
- One can also use the stacking of different models to get more accurate results.
Get hands-on with the above techniques to solve the puzzle. Feel free to reach out to us in case you find any struggle.
We, at Seaflux, are AI & Machine Learning enthusiasts, who are helping enterprises worldwide. Have a query or want to discuss AI projects? Schedule a meeting with us here, we'll be happy to talk to you.

Jay Mehta
Director of Engineering