NLTK vs spaCy - Python based NLP libraries and their functions
Natural Language Processing (NLP) Introduction
NLP, a part of data science, aims to enable machines to interpret and analyze the human language and its emotions to manipulate and provide good interactions. With useful NLP libraries around, NLP has searched its way into many industrial and commercial use cases. Some of the best libraries that can convert the free text to structured features are NLTK, spaCy, Gensim, TextBlob, PyNLPI, CoreNLP, etc.
From the above libraries, we can use multiple NLP Operations. All the libraries have their own functionality and method.
In this blog, we understand the difference between two NLP(Natural Language Processing) libraries, that is spaCy and NLTK (Natural language Toolkit).
What are spaCy and NLTK?
What is spaCy?
- spaCy is implemented in Cython and developed by Matt Honnibal. It is an open-source library for advanced Natural Processing Library(NLP) in python.
- If you are working with lots of text and need to know what is the text about, which words belong to who, or what is the context in the text, then spaCy is quite helpful. It can also find similar text and search for any specific word in the text. Many more tasks can be performed by spaCy, like sentence detection, tokenization, lemmatization, etc.
What is NLTK?
- NLTK refers to Natural language ToolKit, an open-source library for python, written by Steven Bird, Edward Loper, and Ewan Klein to use in development and education. Many tasks can be performed by NLTK, like tokenizing, parse tree, visualization, etc.
- It has tons of algorithms from which we can choose any to perform a task. NLTK supports stemming, Part-Of-Speech (POS), entity recognition, etc.
What are the differences between spaCy and NLTK?
Here is the 2-column breakdown formatted to match the exact structure in your image:
|
Free Guide
AI Implementation Guide: From Idea to Production
A practical guide for technical leaders planning their first AI product. Covers tools, decisions, and mistakes to avoid.
|
Fundamental NLP processing tasks
Now, let’s understand some fundamental tasks of NPL i.e. Word Tokenization, Sentence Tokenization, Stop Words Removal, Stemming, and Lemmatization with the help of spaCy and NLTK in Python.
Word Tokenization:
It is the most commonly used tokenization technique where with the use of a delimiter, it breaks a text into words. The most commonly used delimiter is space. However, more than one delimiter can also be used, like space and punctuation marks.
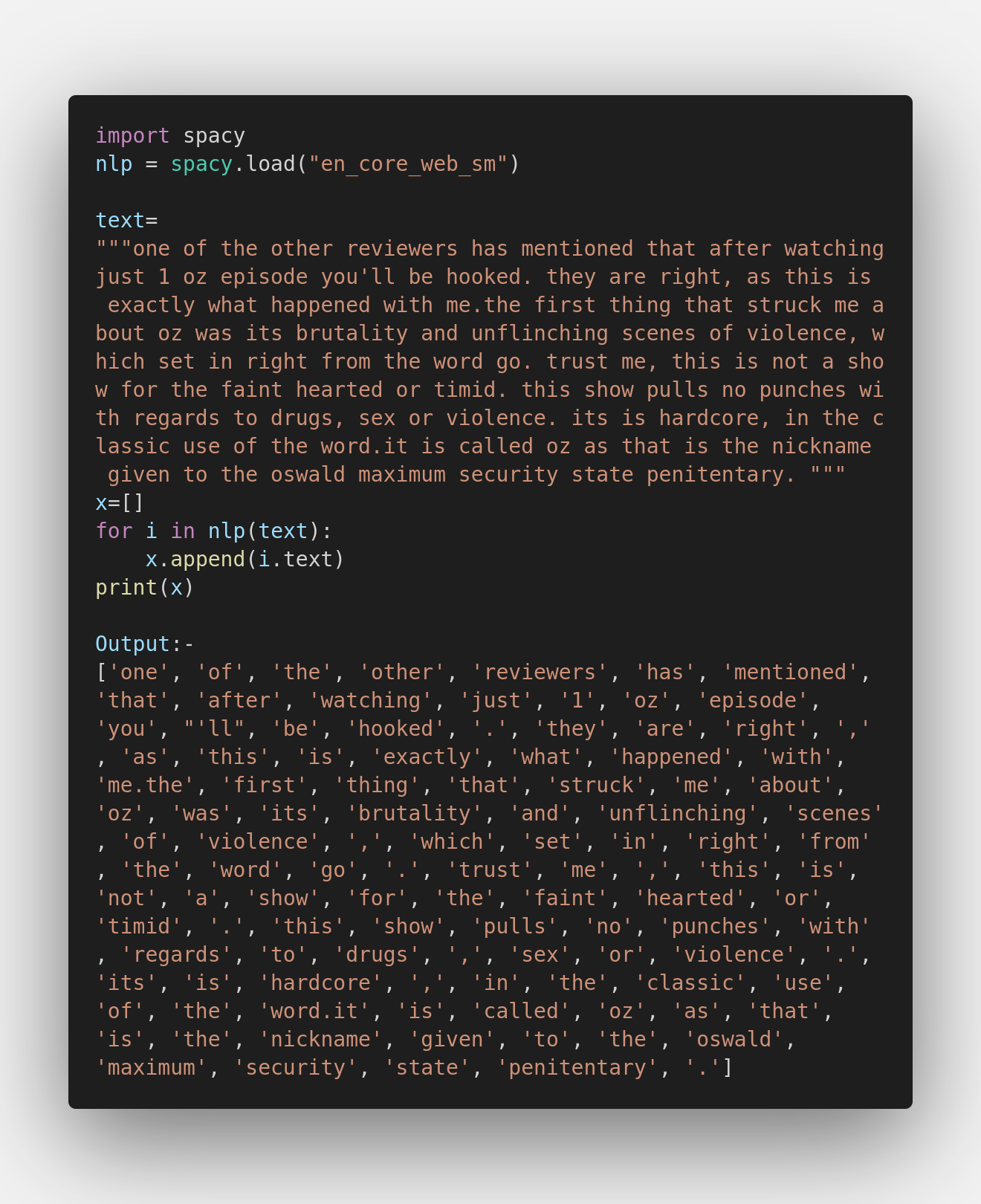
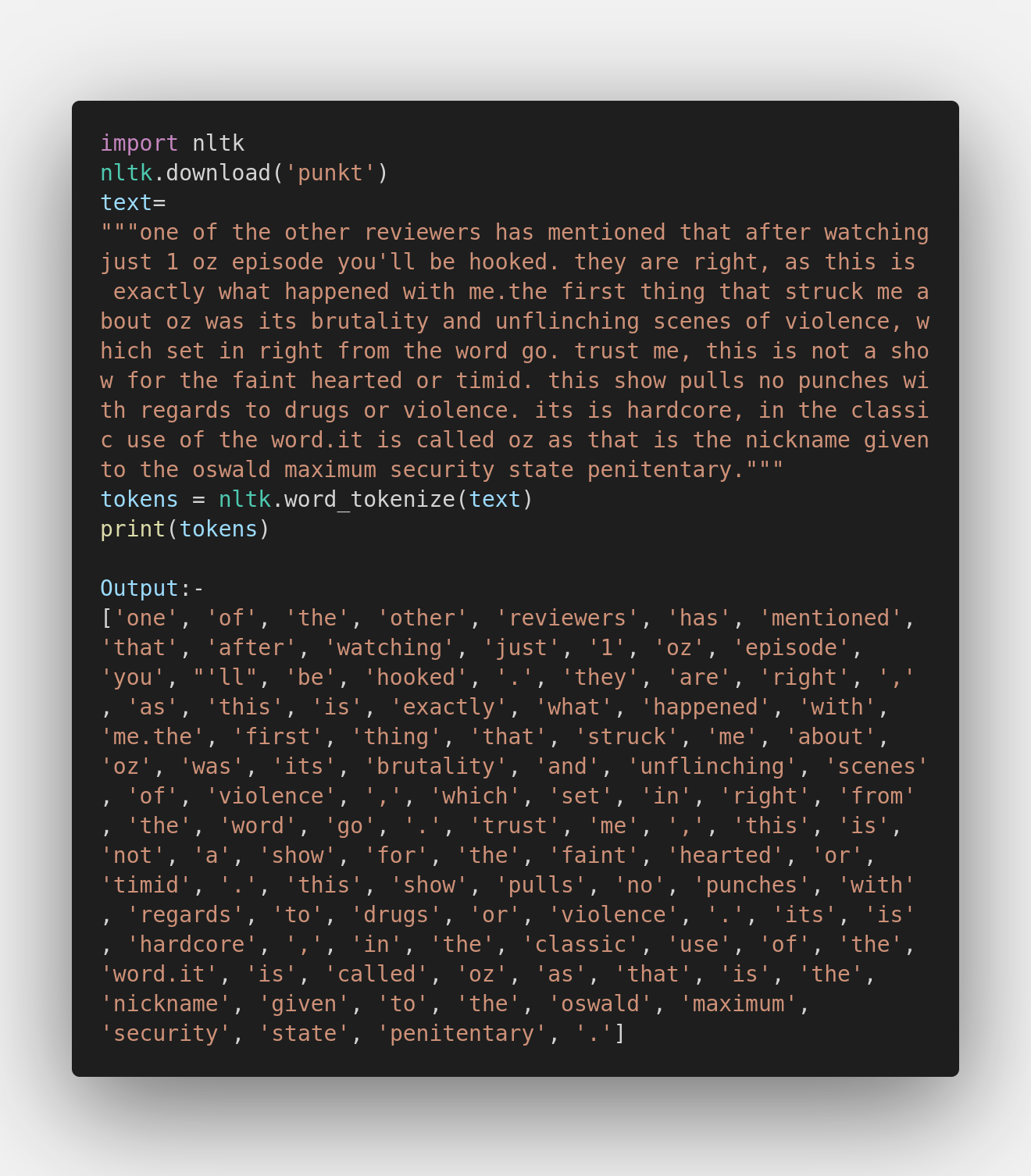
In both the examples, there is no significant change in the output, and both the libraries work just fine. Using either library will get your job done.
Sentence Tokenization:
Sentence tokenization takes a text and splits it into individual sentences. For literature, journalism, and formal documents the tokenization algorithms built into spaCy perform well, since the tokenizer is trained on a corpus of formal English text. The sentence tokenizer shows poor performance for electronic health records featuring abbreviations, medical terms, spatial measurements, and other forms not present in standard written English.
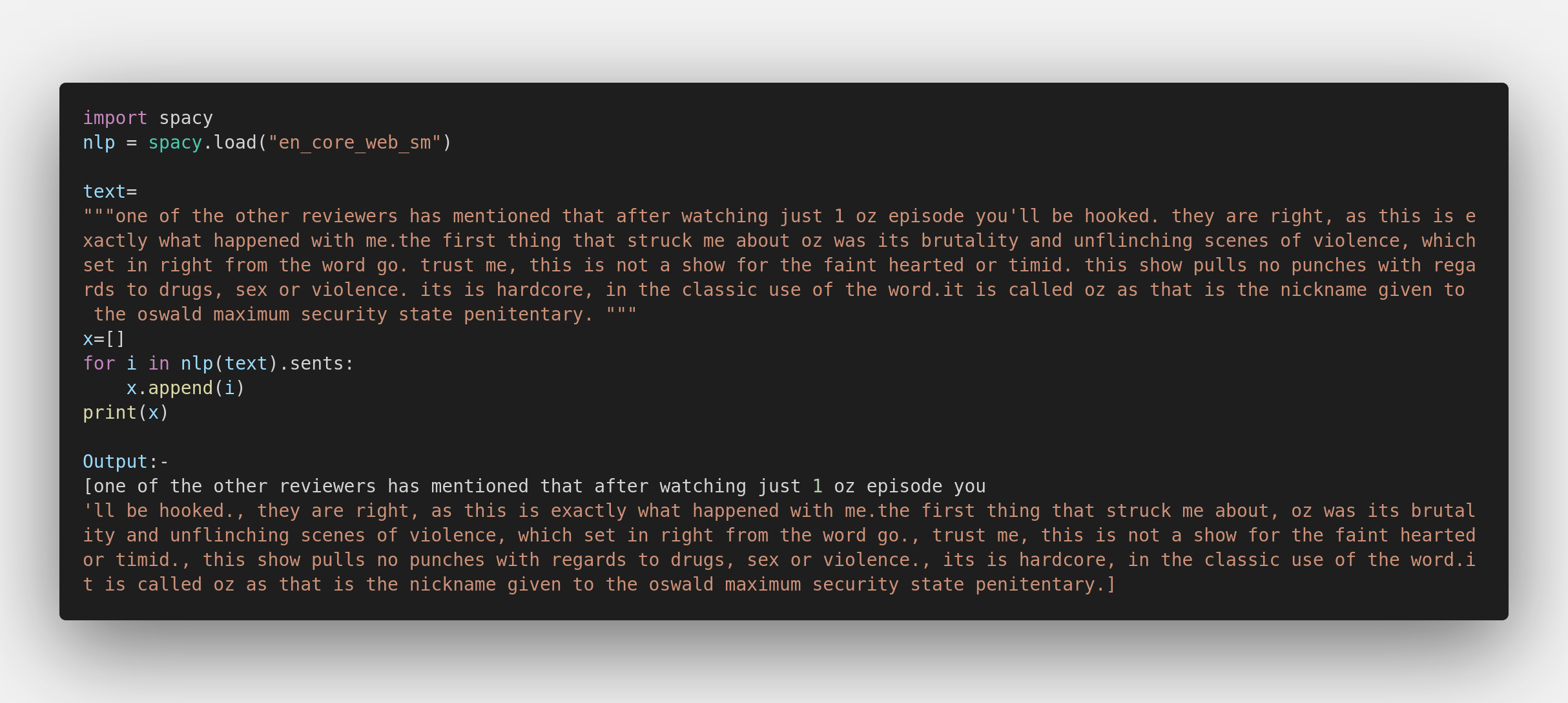
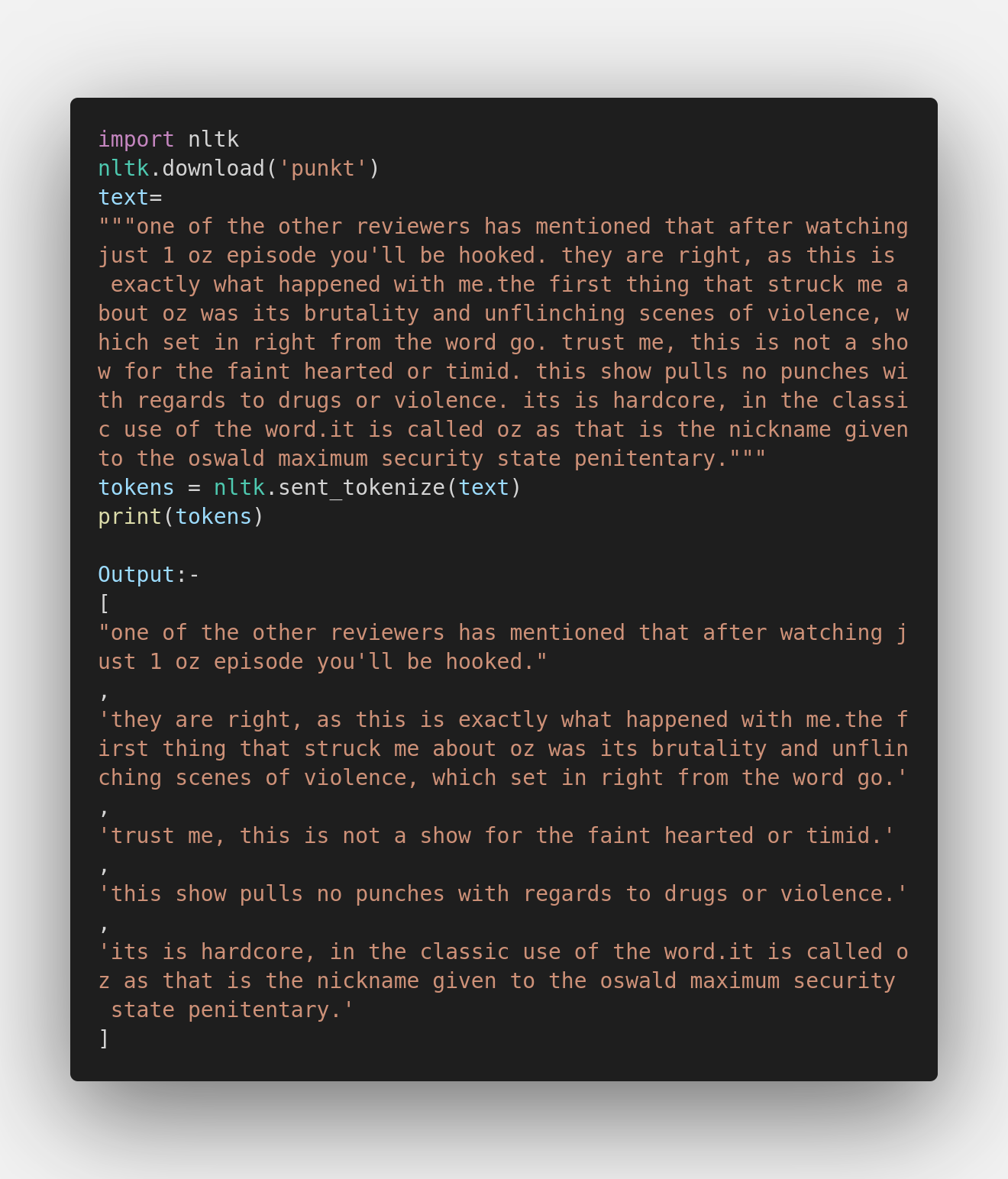
From the example, we can figure out that spaCy has considered that whole sentence after the apostrophe (‘) to be a single sentence, making it ineffective in the sentences where apostrophes are regular. Whereas, NLTK has separated the sentences quite well with minor setbacks.
Remove Stop Words:
StopWords are English words that do not add much meaning to a sentence, so we can remove all the stop words from the text. E.g. “a”, ”the”, ”have”, ”an” etc…
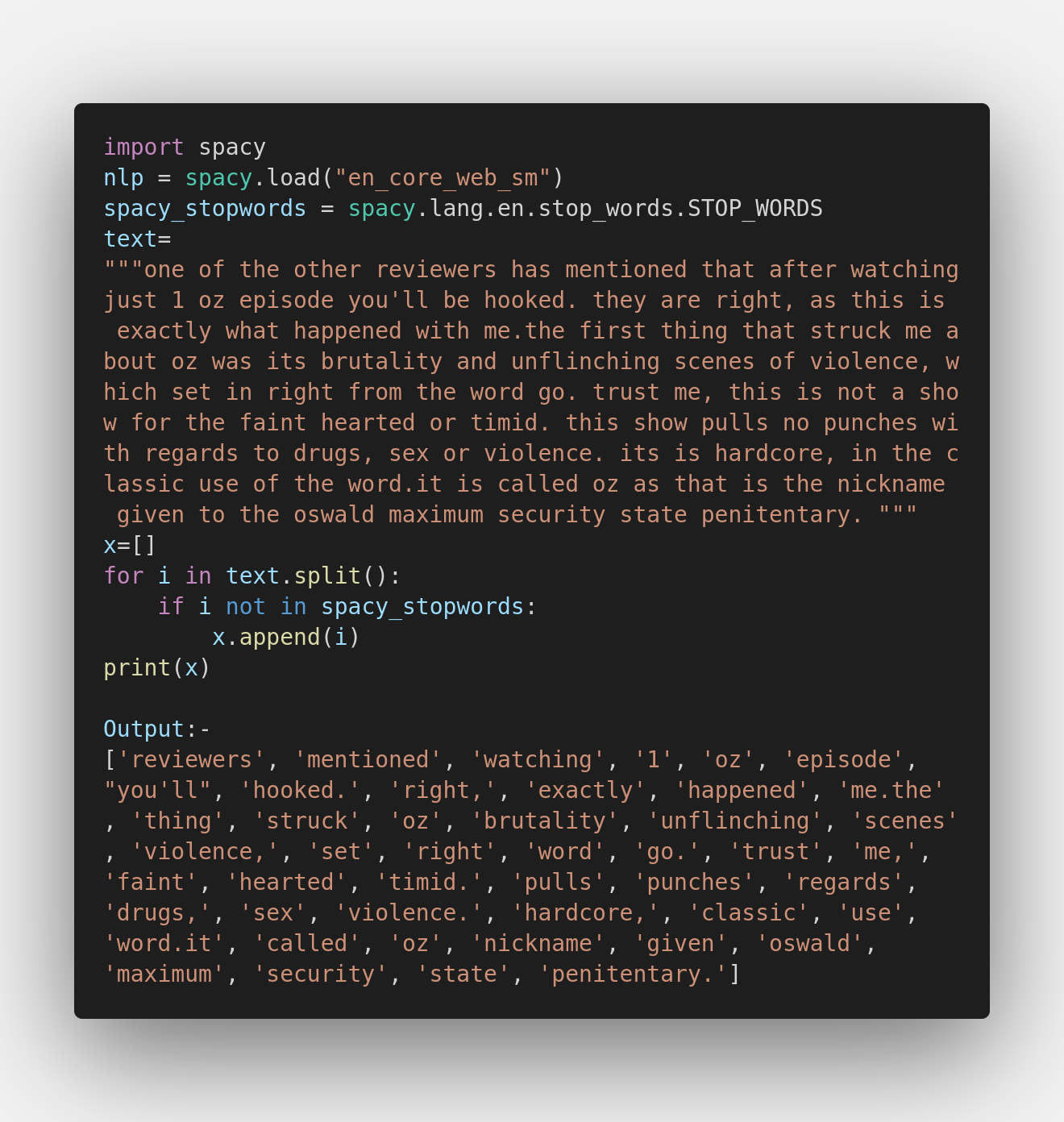
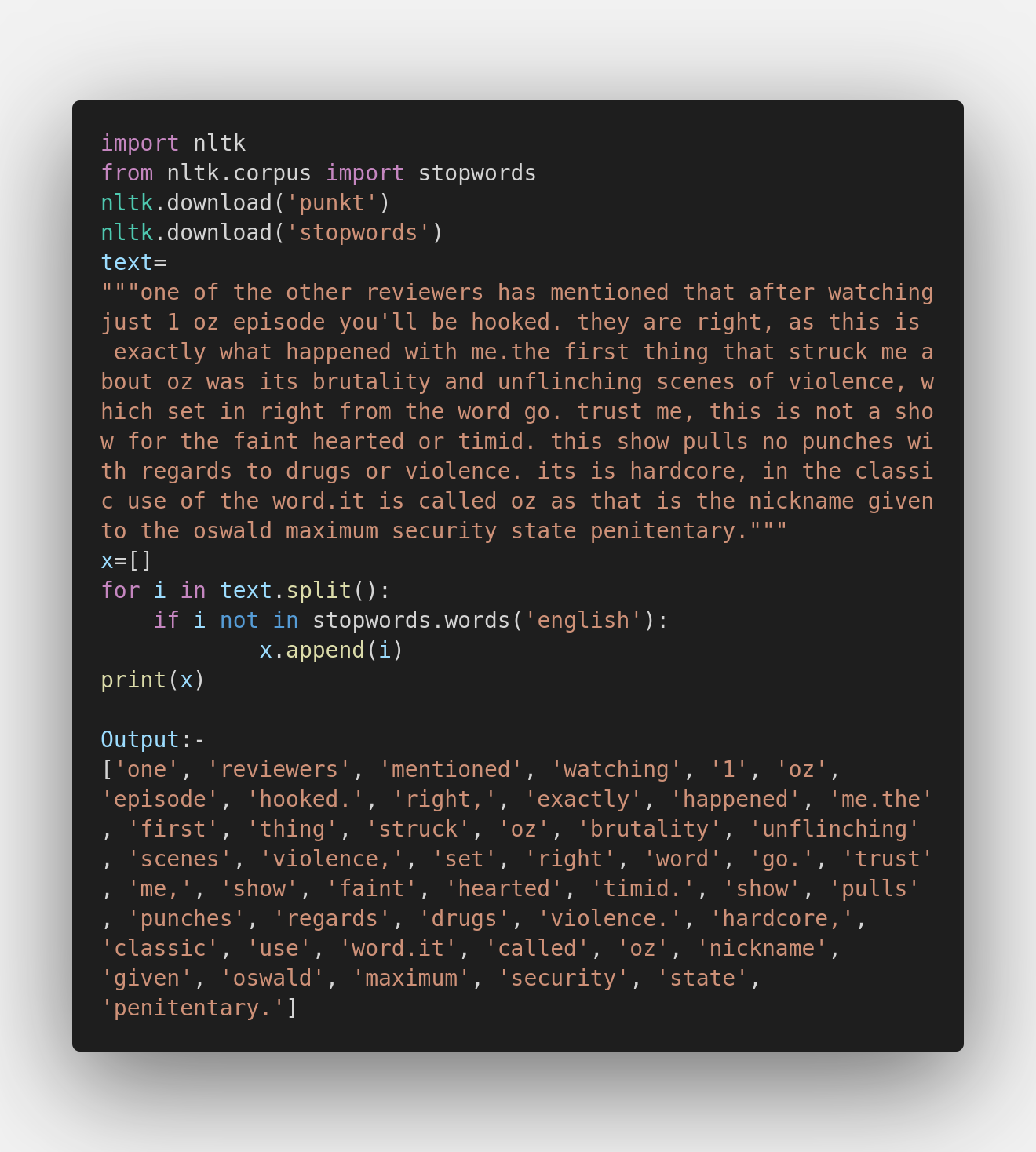
Both the libraries, spaCy and NLTK have done a decent job in removing the stop words from the paragraph. Both can get your task done quite efficiently. However, to pick a winner, spaCy has done better in the segment which is quite accurate. Moreover, NLTK requires downloading the required package to perform the task.
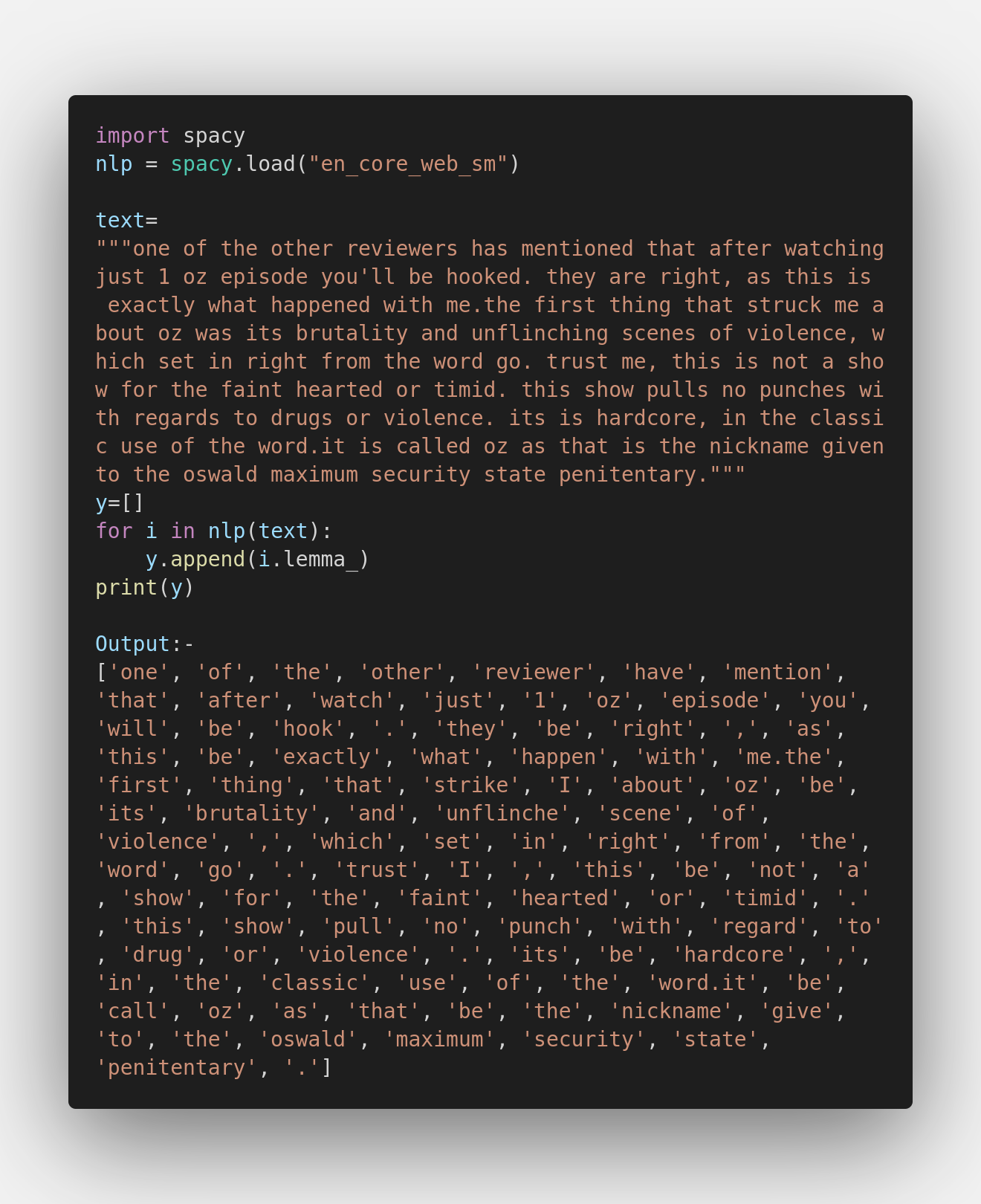
Lemmatization:
Lemmatization is the text normalization technique for spaCy, that will remove words having the same meaning. It is a process of getting the base word of a given word i.e. “counter”, ”count”, so here the base word is “count”.
Stemming:
Stemming is the process of producing morphological variants of a base word. Stemming algorithms and stemming technology are called stemmers. NLTK has a built-in stemmer algorithm called “PorterStemmer” which we have used in the below code. This process is very useful when we are developing a Natural language Processing algorithm. Stemming is the counterpart of spaCy’s Lemmatization.
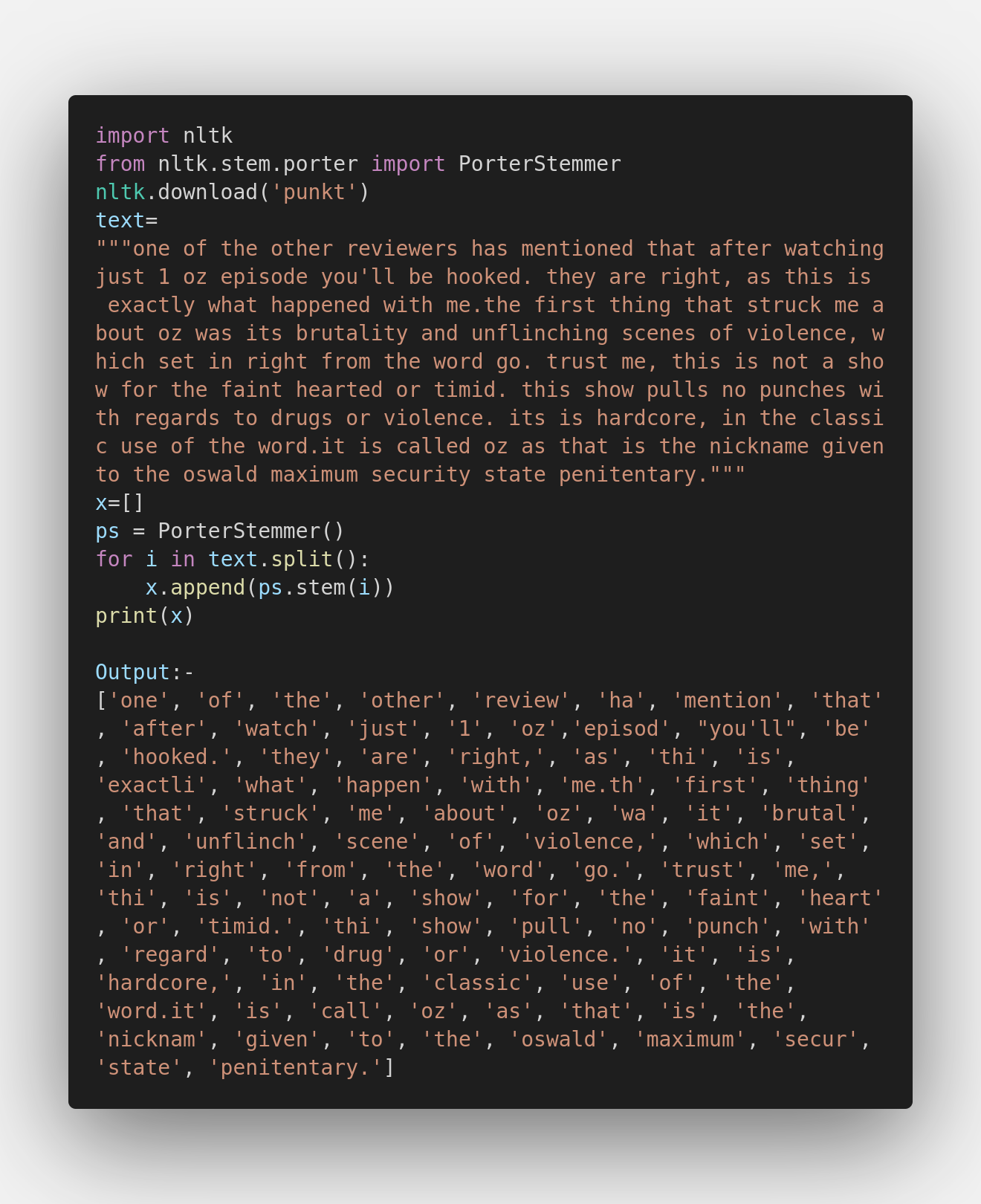
Considering both Lemmatizations and Stemming, I believe that Lemmatization has done a better job in neutralizing the words to their base form, whereas, stemming has changed the meaning of the words by truncating the vowels in the end. This makes NLTK inferior to spaCy in the segment.
End Note
NLTK and spaCy both are very good libraries for building an NLP system. As compared to NLTK, spaCy is more useful in the development and production environment because it provides a very fast and accurate semantic analysis compared to NLTK. Researchers usually prefer to use NLTK because it has a variety of algorithms and with that algorithms, some tasks are very easy to perform. Hence, the best library to use for your project entirely depends on your use case, making the developer move more towards spaCy and researchers towards NLTK.
We, at Seaflux, are AI & Machine Learning enthusiast who is helping enterprises worldwide. Have a query or want to discuss AI or Machine Learning projects? Schedule a meeting with us here, we'll be happy to talk to you!

Jay Mehta
Director of Engineering